VAST Event Broker 101#
VAST EventBroker Overview#
The VAST DATA EventBroker The VAST DATA EventBroker is a modern, high-performance event streaming platform designed as a powerful alternative to Apache Kafka. Built on the scalable and efficient VAST Data Platform, it offers a Kafka-compatible API while fundamentally re-architecting the underlying system to overcome the limitations of traditional Kafka deployments. This innovative approach delivers significant improvements in performance, scalability, and cost-efficiency for real-time data pipelines and AI-driven applications.
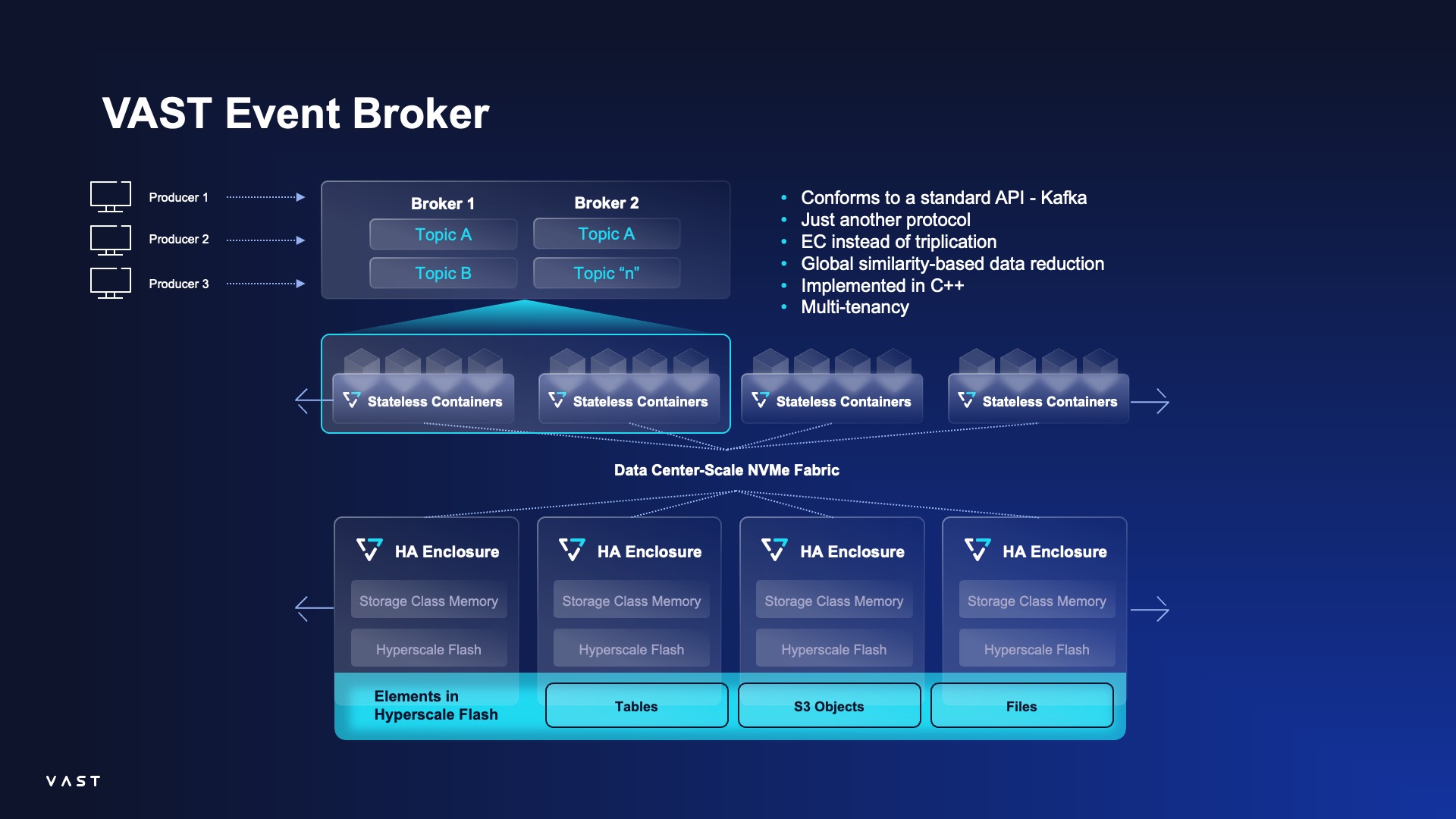
Key Features and Architecture At its core, the EventBroker leverages a disaggregated and shared-everything (DASE) architecture. Unlike traditional Kafka, which co-locates compute and storage on the same broker nodes, VAST separates these two layers. This allows for independent and granular scaling of compute resources (the “brokers”) and storage capacity, eliminating common bottlenecks and simplifying cluster management.
Key advantages of this design include:
Kafka Compatibility: The EventBroker presents a compatible Kafka API. This means existing producers, consumers, and applications that use the Kafka protocol can connect.
Enhanced Performance: By running on an all-flash, high-performance data platform, the EventBroker dramatically reduces latency and accelerates metadata operations. This results in faster message processing and more responsive real-time analytics.
Simplified Management: The underlying VAST Data Platform handles data placement, protection, and tiering automatically. This eliminates the manual and often complex tasks associated with managing Kafka, such as partition rebalancing, data replication, and tiered storage configurations.
Lower Total Cost of Ownership (TCO): With its efficient data reduction capabilities and the ability to scale storage and compute independently, the EventBroker provides a more cost-effective solution for storing and processing vast streams of event data over long periods. It effectively creates an “infinite” retention window without the performance penalties of traditional tiered storage.
In essence, the VAST DATA EventBroker combines the ubiquity of the Kafka API with a next-generation data platform, offering a powerful, scalable, and simplified solution for enterprise event streaming needs.
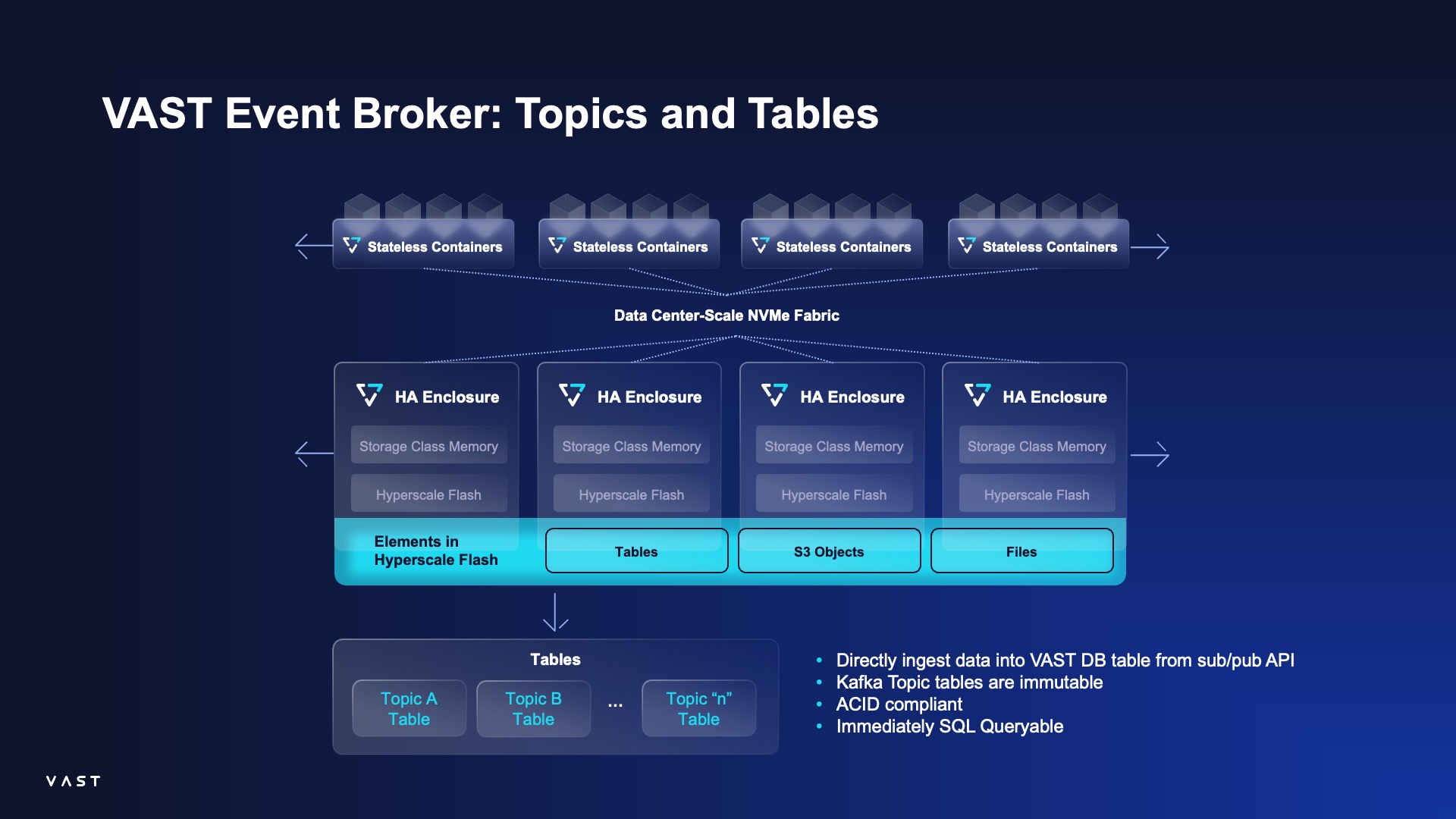
Architecture Overview The VAST Event Broker leverages VAST DB as its persistence layer, creating a direct pathway from an event stream to a queryable table. This integration enables SQL-based analysis on streaming data.
Querying with Trino Once data is persisted in VAST DB, you can connect a distributed SQL query engine like Trino to it. This allows you to run standard SQL queries against the event data
VAST EventBroker Use Cases#
📊 Realtime Analytics#
Description: Streaming event logs for immediate processing.
Use Cases:
Fraud detection
Personalized customer support
Inventory optimization
Cyberlake Threat Intelligence Integration
📡 IoT Data#
Description: Device telemetry data for real-time processing.
Use Cases:
Fleet management
Warehouse sensor tracking
Shipping and logistics management
🔔 Notification Systems#
Description: Event-driven user updates.
Use Cases:
App notifications
Order updates
🤖 AI Pipelines#
Description: Streaming data to models for real-time training or inference.
Use Cases:
Real-time anomaly detection in healthcare
Predictive analytics in finance
VAST EventBroker Concepts#
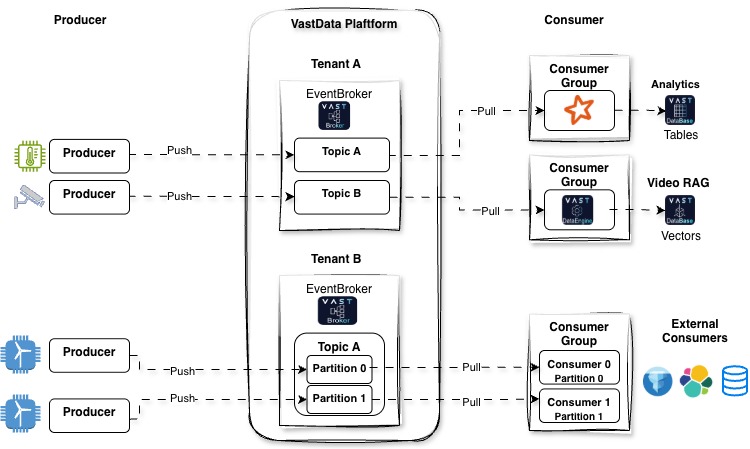
The Core Components: Events, Topics, Partitions, and Offsets:
Event: The fundamental unit of data in Kafka. An event, often called a message, represents a single piece of information. It consists of a key, a value, a timestamp, and optional metadata headers.
Topic: A logical channel or category to which events are published. Think of a topic as a table in a database, but for a continuous stream of data. Producers write events to topics, and consumers read events from them.
Partition: To enable scalability and parallelism, topics are divided into one or more partitions. Each partition is an ordered, immutable sequence of events. Events are appended to the end of a partition’s log. By distributing partitions across different servers, Kafka can handle a massive amount of data.
Offset: Each event within a partition is assigned a unique, sequential ID number called an offset. The offset serves as a pointer to a specific event within that partition, allowing consumers to track their progress and resume reading from where they left off.
The Players: Producers and Consumers:
Producers: These are client applications responsible for creating and sending events to Kafka topics. Producers can choose to send events to a specific partition or allow Kafka to distribute them based on the event’s key.
Consumers: These are client applications that subscribe to one or more topics to read and process the events. Consumers read events in the order they were written to a partition.
Consumer Groups: Consumers can be organized into consumer groups. Each consumer within a group is assigned a unique set of partitions from the subscribed topics, allowing for parallel processing of the data. This is a key feature for achieving high-throughput consumption.
VAST EventBroker Infrastructure The VAST EventBroker system is built on a distributed architecture of brokers that work together in a cluster to provide a scalable and fault-tolerant event streaming service.
Core Components Broker: A single server in the system is called a broker. It is responsible for handling all the core tasks: receiving events from producers, storing them securely, and serving them to consumers.
Cluster: A cluster consists of one or more brokers operating as a team. This distributed setup ensures high availability and scalability. If one broker fails, the others automatically take over its responsibilities, preventing downtime.
VAST Architectural Model In VAST’s implementation, brokers are organized and accessed through Views and VIP Pools.
Views: Each VAST EventBroker Cluster is associated with a view, which defines the specific storage location where the broker will organize messages into topics and partitions in the VAST ElementStore.
VIP Pools: To make the broker accessible on the network, its view is assigned to a VIP Pool. This is a collection of Virtual IP addresses (VIPs) that are distributed across a set of compute nodes (CNodes). Client applications connect to the broker using a bootstrap server list, which is composed of the IP addresses from this VIP Pool.
Multi-Tenancy and Network Isolation A single VAST Cluster can support multiple, independent EventBroker Clusters, making it ideal for multi-tenant environments where different users or applications require their own dedicated broker cluster.
You can enforce network isolation by assigning VIP Pools to specific CNodes. This separation can be done physically through different network segments or logically using VLANs, ensuring traffic remains segregated.
Design Considerations#
The table outlines the design considerations and limitations for a VAST Cluster’s EventBroker system. Think of these as the fundamental rules or architectural boundaries of the platform. They define the maximum capacity and operational limits for key components like topics, partitions, and messages.
Capacity Parameter |
Limit |
Comments |
|---|---|---|
Max number of EventBrokers per VAST Cluster |
512 |
Bounded by the number of VIP Pools per Cluster |
Max partitions per EventBroker |
200000 |
The total number of partitions managed by a broker across all topics |
Consumer Group API - Max consumer groups per EventBroker |
256 |
The maximum number of consumer groups per EventBroker |
Max number of Topics per EventBroker |
10000 |
At least 10K topics per view. Bounded by the size of the reply to the Metadata API request |
Max partitions per topic |
20000 |
The number of partitions in a topic cannot be changed after the topic |
Max number of events per partition |
\(2^{48}\) |
Currently this is also the max that can be ingested in the lifetime of the partition. |
Producer API - Max message size |
1MB |
This refers to the maximum allowable size for a single message that can be sent by a Kafka producer. It’s a critical configuration that impacts performance, resource utilization, and the types of data that can be transmitted through the system. This Limit will be increase to multiple MBs in the next VAST 5.5 release |
Producer API - Keys and Values in event records within messages (including keys and values in event record headers) |
125KB each |
Each message sent via the Producer API—structured with a key for routing, a value for the payload—is currently limited to 125KB, but this limit will increased to multiple MB in the next VAST 5.5 release |
Partitions in Apache Kafka#
A partition is the fundamental unit of parallelism and scalability in Kafka. When you create a topic, you split it into one or more partitions. Think of a topic as a category of messages (like user_signups), and each partition as an independent, ordered log file within that category.
``
Key Concepts#
Ordered Log: Each partition is an immutable, append-only sequence of records. Messages written to a partition are assigned a sequential ID number called an offset, which uniquely identifies each record within that partition. This guarantees the order of messages within a single partition.
Parallelism: Splitting a topic into multiple partitions allows multiple consumers to read from that topic simultaneously. In a consumer group, each consumer can be assigned one or more partitions, enabling parallel processing and dramatically increasing read throughput. 🚀
Scalability: If you need to increase the read/write capacity for a topic, you have to create a topic with multiple partitions to scale out your consumer applications accordingly. This allows Kafka to handle massive message volumes.
How Messages are Assigned to Partitions#
When a producer sends a message to a topic, Kafka needs to decide which partition to write it to. This is typically done in one of three ways:
By Message Key (Most Common): If a message includes a key (e.g., a
user_idororder_id), Kafka will hash the key to determine the partition. This ensures that all messages with the same key will always go to the same partition. This is crucial for guaranteeing the order of related events. ⛓️Round-Robin: If no message key is provided, Kafka will distribute messages across all available partitions in a round-robin fashion to ensure an even load balance.
Custom Partitioner: You can implement your own logic to decide how messages are assigned to partitions based on specific business rules.
Designing Topics: The Importance of Partitions#
When designing your topics, the number of partitions is a critical parameter that directly impacts parallelism and throughput. While the system supports up to 1,000 partitions per topic, a well-chosen number is key to optimal performance.
A good rule of thumb is to configure more partitions than the number of silos per CNode (the compute nodes in the VAST cluster). This ensures that workloads can be spread evenly across all available processing units, preventing hotspots and maximizing parallel processing capabilities.
Recommendations Recommended Baseline: Start with at least 40+ partitions per topic.
Optimal Performance: For many use cases, a higher count of around 100 partitions is even better, as it provides greater flexibility for consumer scaling and load distribution.
By over-provisioning partitions relative to the physical compute resources (silos), you enable the system to distribute data and processing more effectively, which is essential for achieving high throughput and low latency.
Kafka API#
Please review the APIs implemented on the VAST Documentation Site [Link coming soon..]
Setup VAST EventBroker#
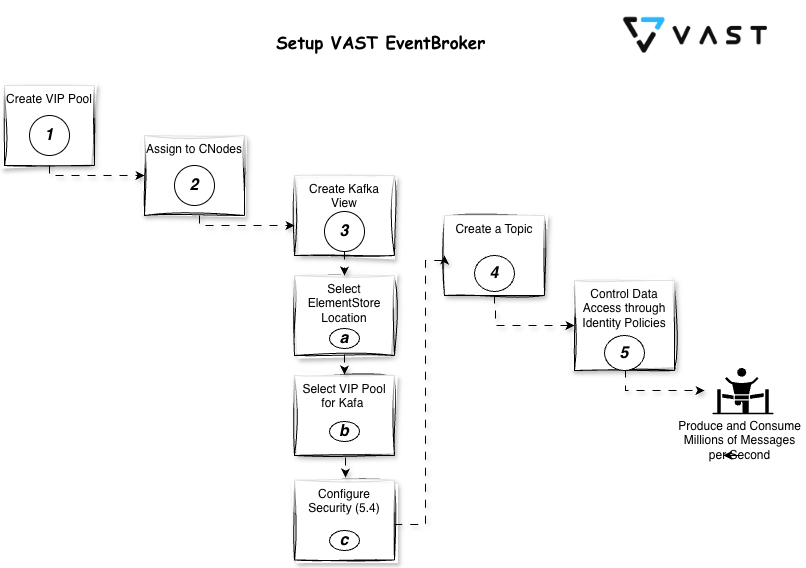
Create VIP Pool#
Configuration Option |
Description |
|---|---|
Name |
A unique identifier for the VIP Pool. |
Tenant |
Specifies which tenant the VIP pool will serve. It can be dedicated to a single tenant or shared across all tenants. |
IP Ranges |
The list of contiguous IP addresses that will be included in the pool. Both IPv4 and IPv6 are supported. |
Subnet CIDR |
The subnet mask for the IP addresses in the pool, defined in CIDR notation. |
Gateway |
The gateway IP address for the VIP pool’s subnet. |
VLAN |
Allows for the tagging of the VIP pool with a specific VLAN ID, enabling network segmentation at Layer 2. |
Role |
Defines the primary purpose of the VIP pool. Common roles include: Protocols (for general data access via NFS, S3, SMB), Replication (for dedicated replication traffic), and Big Catalog (for optimizing metadata queries). |
CNode Affinity |
Determines which CNodes will host the VIPs in the pool. This can be all CNodes in the cluster or a specific subset, which is useful for isolating workloads or dedicating more powerful hardware to demanding applications. |
Port Membership |
Specifies which network ports on the assigned CNodes (e.g., left or right) will be used for the VIPs in the pool. |
VMS Preferred |
Indicates that the CNodes in this pool are preferred for running the VAST Management Service (VMS), influencing failover decisions for the management interface. |
VIP Pool Domain Name |
When using the VAST DNS service, this assigns a domain name to the VIP pool, allowing for DNS-based load balancing and simplified client configuration. |
By leveraging these configuration options, administrators can create a highly flexible and resilient network architecture that aligns with their application performance, security, and data segregation requirements.
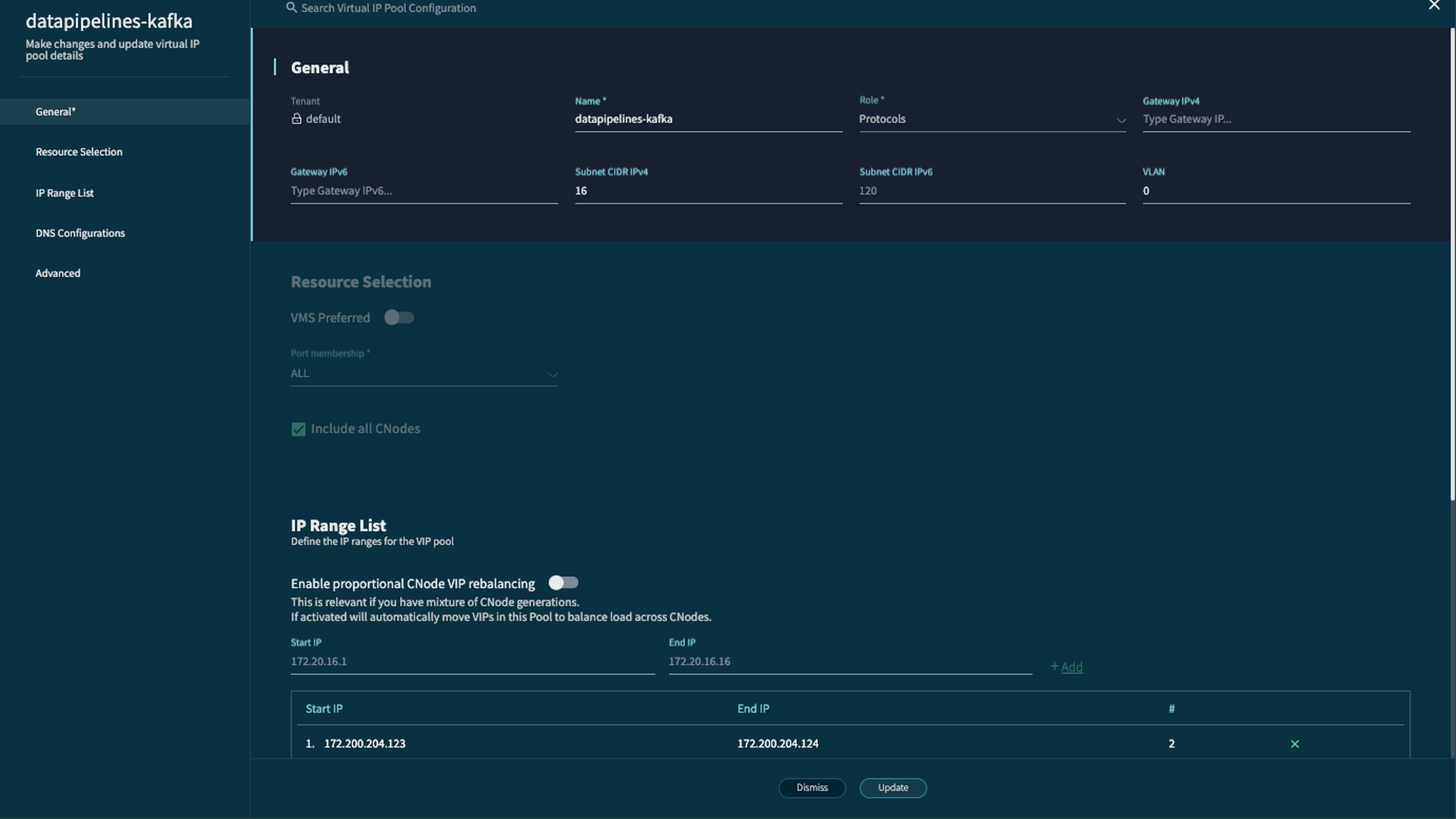
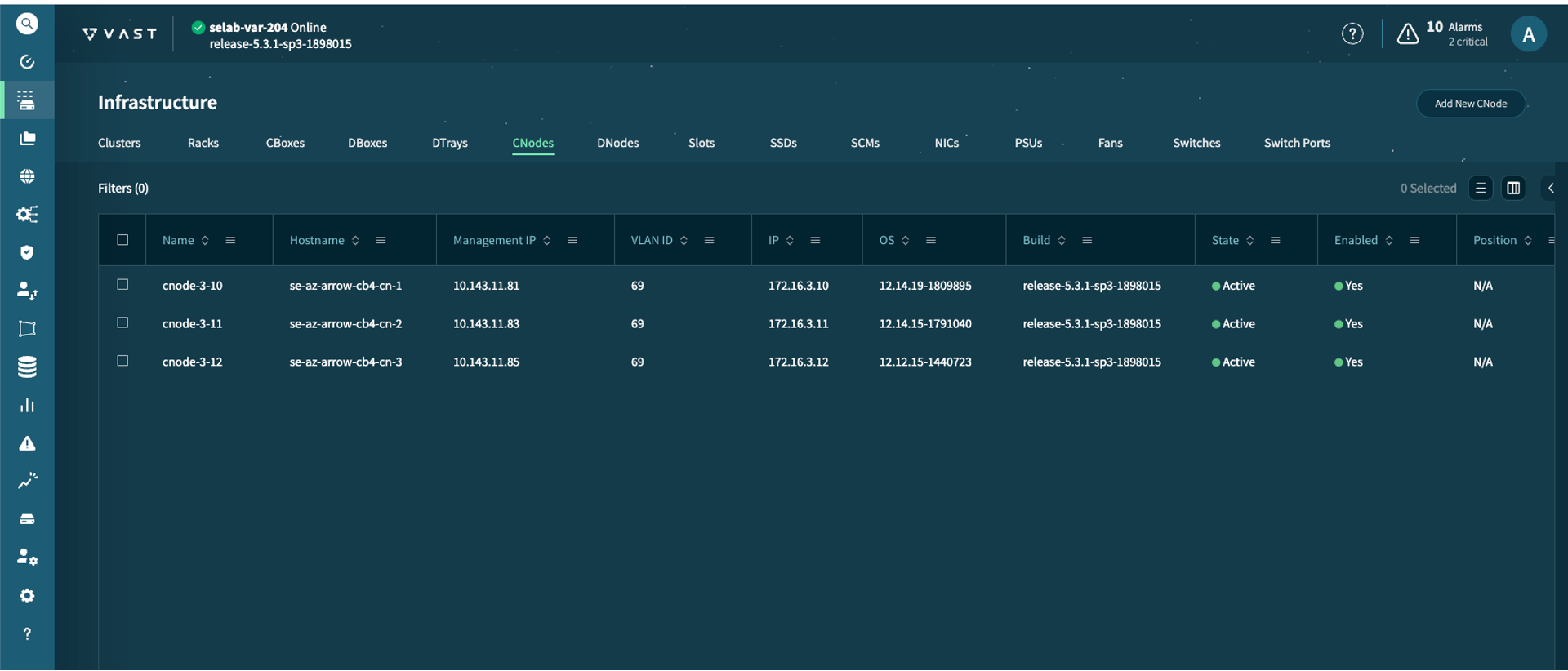
Assign CNodes to VIP Pool#
Advantage of CNode Affinity CNode Affinity is the ability to dedicate a specific group of CNodes to a particular workload or tenant via a VIP Pool. This provides several key benefits:
Guaranteed Performance: Ensures critical applications always have the compute power they need.
Workload Isolation: Prevents a busy application from slowing down others.
Enhanced Security: Isolates traffic by dedicating CNodes to specific network segments.
Hardware Optimization: Allows you to assign the most demanding jobs to your most powerful hardware.
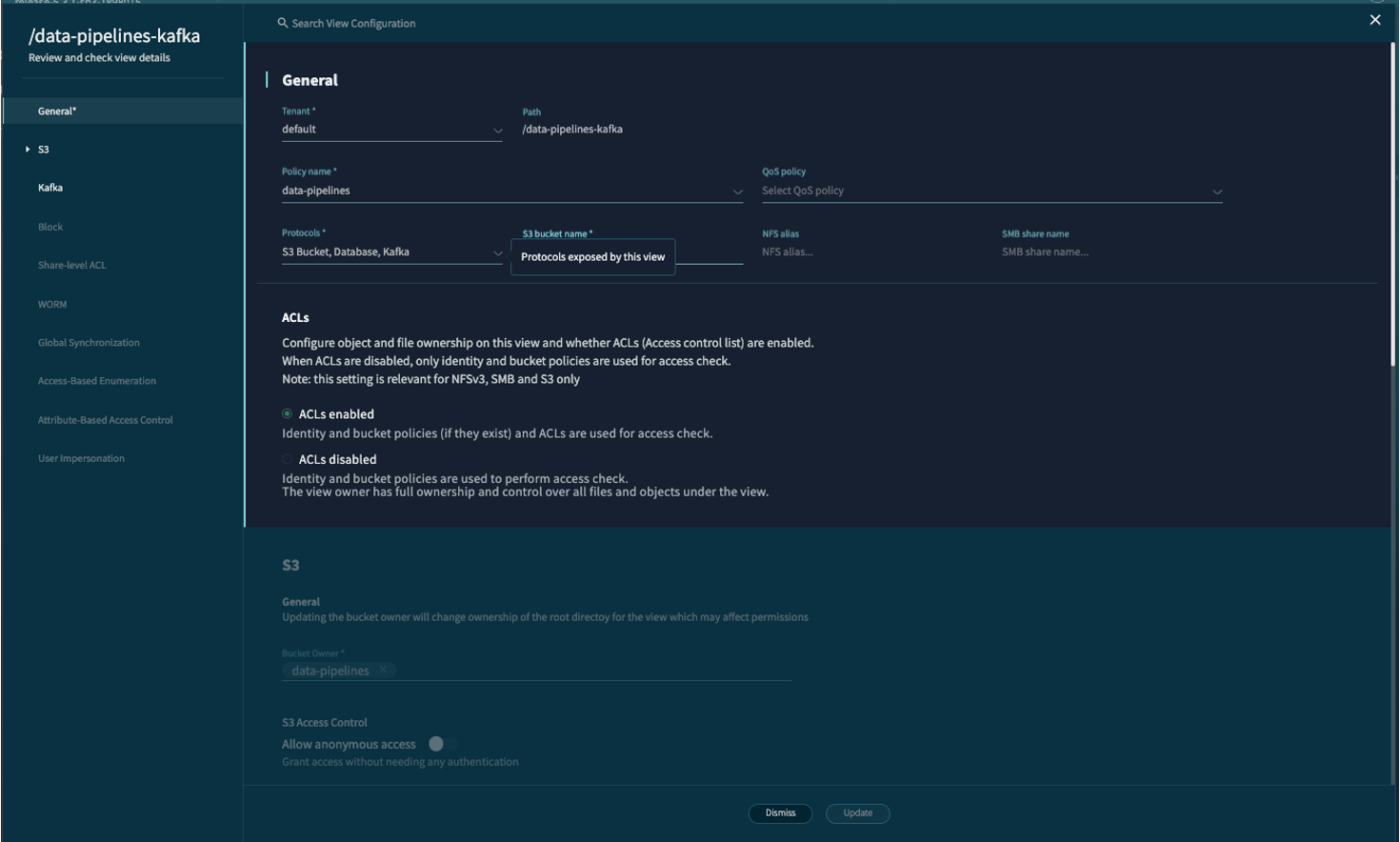
Create Kafka View#
Using the VAST Web UI:
Navigate to Element Store > Views.
Click Create View.
In the General tab:
Enter a Name for your view.
Provide the Path on the VAST cluster that this view will expose (e.g.,
/kafka-data).From the Protocols dropdown, select KAFKA.
Select the View Policy you created earlier.
Click Create.
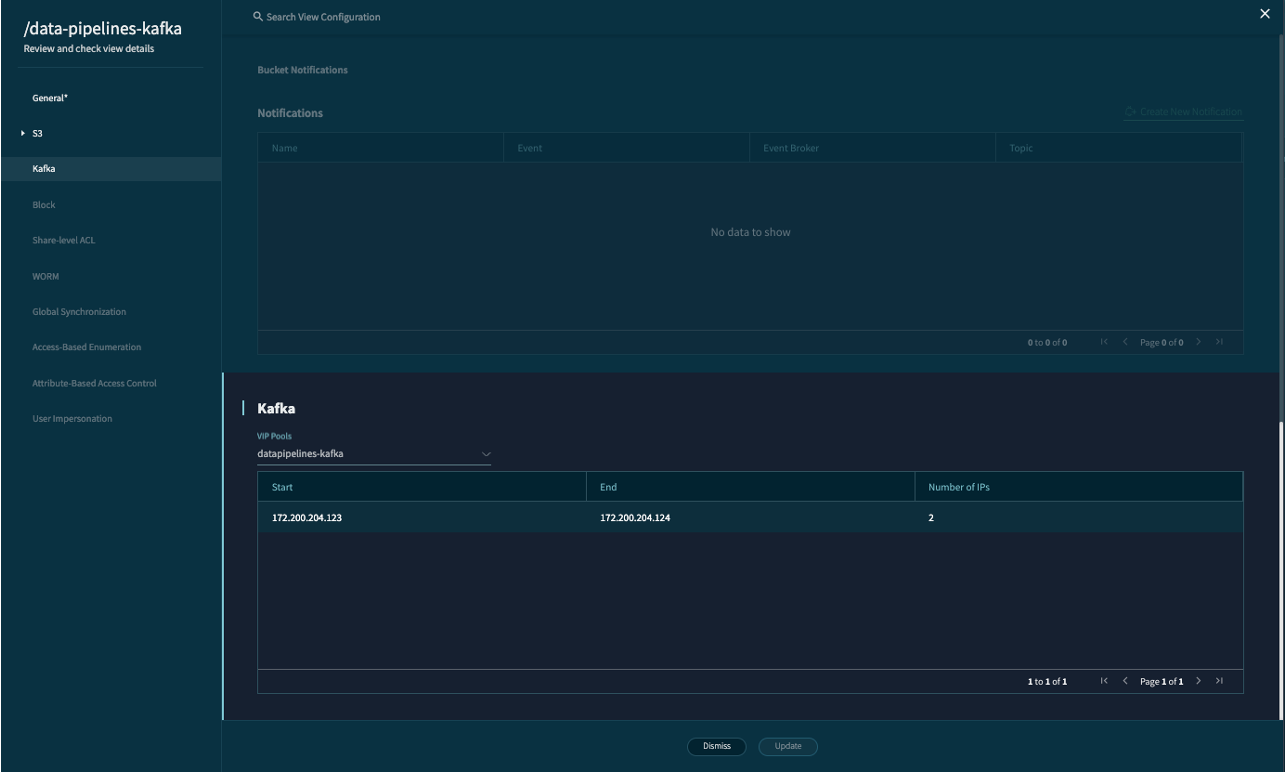
Go to the Kafka tab:
From the VIP Pools dropdown, select the VIP pool you created.
Click Create.
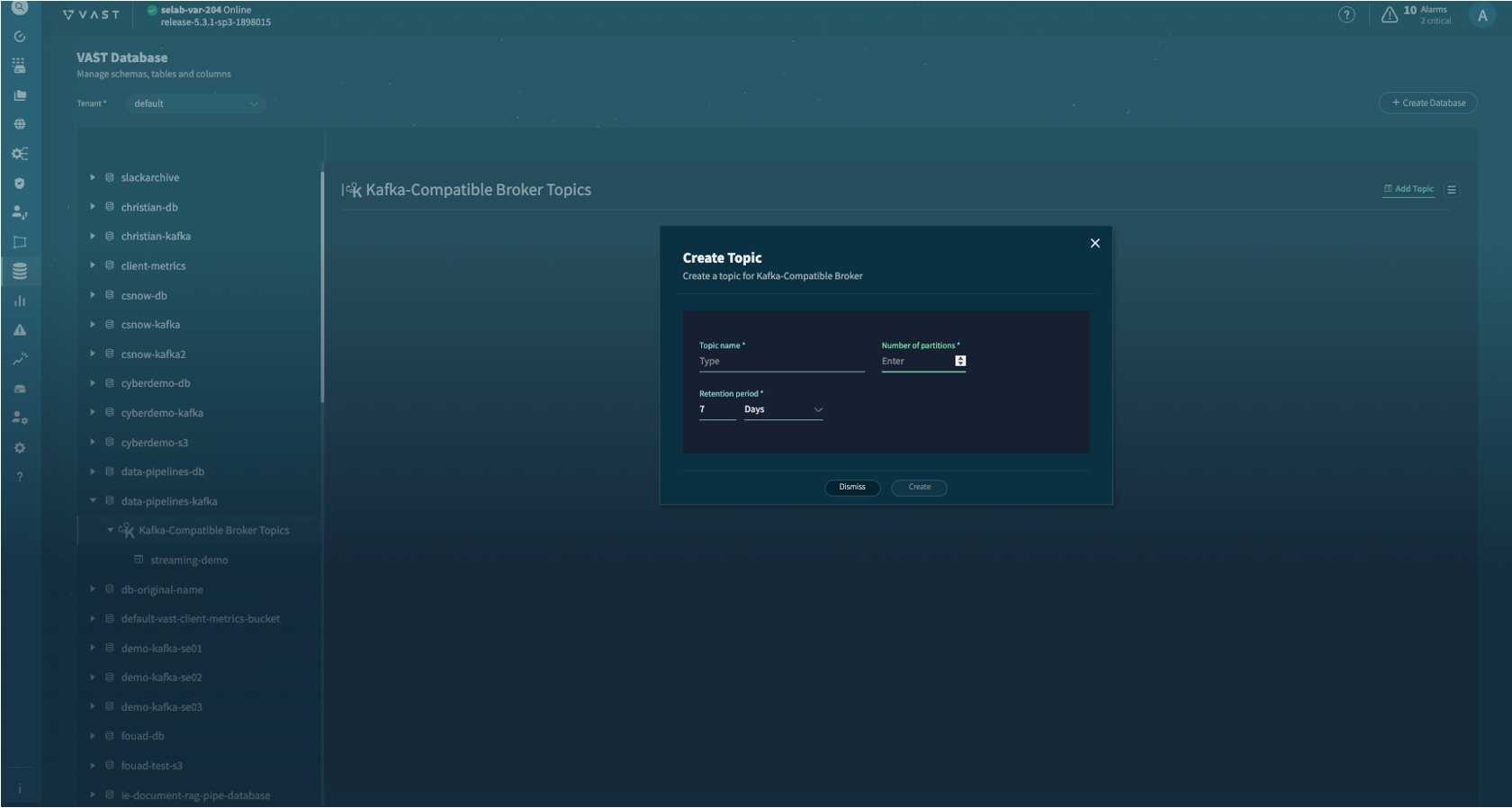
Create a Topic#
Once the Kafka-enabled view is created, a corresponding VAST Database is automatically generated. You can then create and manage Kafka topics within this database.
Using the VAST Web UI:
Go to DataBase > VAST Database.
Locate the database named after your Kafka-enabled view and expand it.
Click on Kafka-Compatible Broker Topics.
Click the Add Topic button.
Provide a Topic Name and specify the Number of Partitions and Retention Period.
Click Create.
VAST EventBroker 101 - Kafka API#
Install Python API#
%%capture --no-stderr
%pip install --quiet -U kafka-python
Configure your environment#
topic_to_create = "cctv"
broker_servers = "172.200.204.244:9092"
Create a topic#
from kafka.admin import KafkaAdminClient
from kafka.admin import NewTopic
from kafka.errors import TopicAlreadyExistsError
def create_kafka_topic(topic_name, num_partitions=1, replication_factor=1, bootstrap_servers='localhost:9092'):
"""
Creates a Kafka topic if it doesn't already exist.
Args:
topic_name (str): The name of the topic to create.
num_partitions (int): The number of partitions for the topic.
replication_factor (int): The replication factor for the topic.
bootstrap_servers (str): Comma-separated list of Kafka broker addresses.
"""
try:
admin_client = KafkaAdminClient(bootstrap_servers=bootstrap_servers)
topic_list = [NewTopic(name=topic_name, num_partitions=num_partitions, replication_factor=replication_factor)]
admin_client.create_topics(new_topics=topic_list, validate_only=False)
print(f"Topic '{topic_name}' created successfully.")
except TopicAlreadyExistsError:
print(f"Topic '{topic_name}' already exists.")
except Exception as e:
print(f"An error occurred: {e}")
finally:
if 'admin_client' in locals():
admin_client.close()
create_kafka_topic(topic_to_create, bootstrap_servers=broker_servers)
create_kafka_topic(topic_to_create, bootstrap_servers=broker_servers) # demonstrating the already exists portion.
Topic 'cctv' created successfully.
Topic 'cctv' already exists.
List topics#
from kafka.admin import KafkaAdminClient
# Define the Kafka broker (adjust the host/port as needed)
# Create an admin client
admin_client = KafkaAdminClient(bootstrap_servers=broker_servers)
# Fetch the list of topics
topics = admin_client.list_topics()
# Print the list of topics
print("Kafka Topics:", topics)
# Close the admin client
admin_client.close()
Kafka Topics: ['cctv']
Show Topic Details#
from kafka.admin import KafkaAdminClient, ConfigResource, ConfigResourceType
from kafka.errors import KafkaError
# --- Configuration ---
# Replace with your Kafka brokers' addresses
def describe_topic_configs(admin_client, topic_names):
"""Describes the configuration for a list of topics."""
config_resources = [ConfigResource(ConfigResourceType.TOPIC, topic) for topic in topic_names]
try:
return admin_client.describe_configs(config_resources)
except KafkaError as e:
print(f"Error describing topic configs: {e}")
return None
try:
# 1. Create the Admin Client
admin_client = KafkaAdminClient(
bootstrap_servers=broker_servers,
client_id='my_admin_client'
)
# 2. Get the list of all topic names
topic_names = admin_client.list_topics()
print(f"Found {len(topic_names)} topics: {', '.join(topic_names)}\n")
print("--- Topic Details ---")
# 3. Describe the topics to get their details
if topic_names:
topic_details = admin_client.describe_topics(topic_names)
topic_configs = describe_topic_configs(admin_client, topic_names)
# 4. Iterate and print the details for each topic
for i, topic in enumerate(topic_details):
topic_name = topic['topic']
print(f"\nTopic: {topic_name}")
print(f" Internal: {topic['is_internal']}")
# Print retention policy
if topic_configs and len(topic_configs) > i:
retention_ms = 'N/A'
for config_entry in topic_configs[i].resources[0][4]:
if config_entry[0] == 'retention.ms':
retention_ms = config_entry[1]
break
print(f" Retention (ms): {retention_ms}")
print(f" Partitions: {len(topic['partitions'])}")
for partition in topic['partitions']:
print(f" - Partition ID: {partition['partition']}")
print(f" Leader: {partition['leader']}")
print(f" Replicas: {partition['replicas']}")
print(f" In-Sync Replicas (ISR): {partition['isr']}")
except KafkaError as e:
print(f"An error occurred: {e}")
finally:
# 5. Close the admin client connection
if 'admin_client' in locals() and admin_client:
admin_client.close()
print("\nAdmin client closed.")
Found 1 topics: cctv
--- Topic Details ---
Topic: cctv
Internal: False
Retention (ms): 604800000
Partitions: 1
- Partition ID: 0
Leader: 1
Replicas: [1]
In-Sync Replicas (ISR): [1]
Admin client closed.
Produce messages#
import json
import random
import uuid
from datetime import datetime, timezone
from kafka import KafkaProducer
# --- Initialize Kafka Producer ---
producer = KafkaProducer(
bootstrap_servers=broker_servers,
value_serializer=lambda v: json.dumps(v).encode('utf-8')
)
# --- Data for Simulation ---
locations = ["Main Entrance", "Parking Lot B", "Warehouse Dock 3", "Lobby", "Floor 2 Hallway"]
event_types = ["Motion Detected", "Person Detected", "Vehicle Entry", "Package Left", "Door Opened"]
print("Sending 10 CCTV event messages to Kafka...")
# --- Generate and Send Messages ---
for i in range(1, 6):
# Create a unique, realistic CCTV event message
data = {
"event_id": str(uuid.uuid4()),
"timestamp": datetime.now(timezone.utc).isoformat(),
"camera_id": f"cam_{random.randint(101, 105)}",
"location": random.choice(locations),
"event_type": random.choice(event_types),
"confidence_score": round(random.uniform(0.85, 0.99), 2),
"objects_detected": [
{
"class": "person",
"bounding_box": [random.randint(100, 150), random.randint(200, 250), random.randint(180, 220), random.randint(400, 450)]
}
]
}
# Send the message
producer.send(topic_to_create, data)
# Print a confirmation to the console
print(f"Sent message {i}: {data['event_type']} at {data['location']}")
# Ensure all messages are sent before exiting
producer.flush()
print("\nAll messages sent successfully to the Kafka topic.")
Sending 10 CCTV event messages to Kafka...
Sent message 1: Motion Detected at Warehouse Dock 3
Sent message 2: Door Opened at Main Entrance
Sent message 3: Person Detected at Main Entrance
Sent message 4: Motion Detected at Parking Lot B
Sent message 5: Vehicle Entry at Lobby
All messages sent successfully to the Kafka topic.
Consume messages#
from kafka import KafkaConsumer
# Assume these variables are defined elsewhere, for example:
consumer = KafkaConsumer(
topic_to_create,
bootstrap_servers=[broker_servers],
auto_offset_reset='earliest',
group_id='cctv_consumer',
# This is the key change:
# Stop iterating if no message is received for 5000ms (5 seconds).
consumer_timeout_ms=5000
)
print("Starting to consume available messages...")
message_count = 0
for message in consumer:
print(f"Received message: {message.value.decode('utf-8')}")
message_count += 1
print(f"\nFinished consuming. Found {message_count} messages.")
# It's good practice to explicitly close the consumer.
consumer.close()
Starting to consume available messages...
Finished consuming. Found 0 messages.
Reprocess Kafka Messages#
from kafka import KafkaConsumer
import time
# Assume these variables are defined elsewhere:
# topic_to_create = "your_topic"
# broker_servers = "localhost:9092"
consumer = KafkaConsumer(
# NOTE: Do not pass the topic here if you plan to seek.
# We will subscribe after initialization.
bootstrap_servers=[broker_servers],
auto_offset_reset='earliest',
group_id='cctv_reprocessing',
# A short timeout is fine for the initial poll.
consumer_timeout_ms=1000
)
# 1. Subscribe to the topic
consumer.subscribe([topic_to_create])
# 2. Poll the consumer to trigger partition assignment.
# This is the crucial step. We poll until we get an assignment.
print("Waiting for partition assignment...")
while not consumer.assignment():
consumer.poll(timeout_ms=1000) # Poll with a timeout
print("Still no partitions assigned, waiting...")
print(f"Partitions assigned: {consumer.assignment()}")
# 3. Now that partitions are assigned, you can safely seek.
print("Seeking to the beginning of all assigned partitions...")
consumer.seek_to_beginning()
# 4. Start consuming messages from the beginning.
print("Starting to consume available messages...")
message_count = 0
# The main loop now starts consuming from the beginning.
for message in consumer:
print(f"Received message: Offset={message.offset}, Value={message.value.decode('utf-8')}")
message_count += 1
print(f"\nFinished consuming. Found {message_count} messages.")
consumer.close()
Waiting for partition assignment...
Still no partitions assigned, waiting...
Still no partitions assigned, waiting...
Still no partitions assigned, waiting...
Partitions assigned: {TopicPartition(topic='cctv', partition=0)}
Seeking to the beginning of all assigned partitions...
Starting to consume available messages...
Received message: Offset=0, Value={"event_id": "b2f3c75c-38d1-4876-84c5-54b97ff9871e", "timestamp": "2025-10-15T05:57:10.452992+00:00", "camera_id": "cam_103", "location": "Warehouse Dock 3", "event_type": "Motion Detected", "confidence_score": 0.94, "objects_detected": [{"class": "person", "bounding_box": [149, 250, 205, 448]}]}
Received message: Offset=1, Value={"event_id": "256fd484-0e20-4b69-b451-218b32858a02", "timestamp": "2025-10-15T05:57:10.559749+00:00", "camera_id": "cam_103", "location": "Main Entrance", "event_type": "Door Opened", "confidence_score": 0.94, "objects_detected": [{"class": "person", "bounding_box": [114, 201, 189, 434]}]}
Received message: Offset=2, Value={"event_id": "eb122bf7-34a3-42e2-adc6-f14e068e74f6", "timestamp": "2025-10-15T05:57:10.559967+00:00", "camera_id": "cam_105", "location": "Main Entrance", "event_type": "Person Detected", "confidence_score": 0.97, "objects_detected": [{"class": "person", "bounding_box": [142, 226, 182, 438]}]}
Received message: Offset=3, Value={"event_id": "94468338-2025-4288-9867-54bf9db74f6c", "timestamp": "2025-10-15T05:57:10.560107+00:00", "camera_id": "cam_102", "location": "Parking Lot B", "event_type": "Motion Detected", "confidence_score": 0.88, "objects_detected": [{"class": "person", "bounding_box": [143, 225, 205, 409]}]}
Received message: Offset=4, Value={"event_id": "2c4f94d3-819e-4aa5-8df6-03e6cd8e1623", "timestamp": "2025-10-15T05:57:10.560272+00:00", "camera_id": "cam_104", "location": "Lobby", "event_type": "Vehicle Entry", "confidence_score": 0.91, "objects_detected": [{"class": "person", "bounding_box": [143, 228, 198, 450]}]}
Finished consuming. Found 5 messages.
List All Consumer Groups on a Broker#
from kafka.admin import KafkaAdminClient
from kafka.errors import NoBrokersAvailable
import sys
# --- Main Script ---
admin_client = None # Initialize to ensure it's defined for the finally block
try:
# 1. Create an Admin Client
print(f"Connecting to Kafka brokers at {broker_servers}...")
admin_client = KafkaAdminClient(
bootstrap_servers=broker_servers,
client_id='my_admin_client'
)
print("Successfully connected to Kafka.")
# 2. List all consumer groups
print("\nFetching consumer groups...")
consumer_groups = admin_client.list_consumer_groups()
if not consumer_groups:
print("No consumer groups found on the broker.")
else:
print(f"\nFound {len(consumer_groups)} consumer groups:")
# The result is a list of tuples: (group_id, protocol_type)
for group_id, protocol_type in consumer_groups:
print(f" - Group ID: {group_id}, Protocol Type: {protocol_type}")
except NoBrokersAvailable:
print(f"Error: Could not connect to any of the specified brokers: {BROKER_SERVERS}", file=sys.stderr)
print("Please ensure the broker address is correct and Kafka is running.", file=sys.stderr)
except Exception as e:
print(f"An unexpected error occurred: {e}", file=sys.stderr)
finally:
# 3. Close the client connection
if admin_client:
print("\nClosing admin client connection.")
admin_client.close()
Connecting to Kafka brokers at 172.200.204.244:9092...
Successfully connected to Kafka.
Fetching consumer groups...
Found 2 consumer groups:
- Group ID: cctv_reprocessing, Protocol Type: consumer
- Group ID: cctv_consumer, Protocol Type: consumer
Closing admin client connection.
Delete Topic#
from kafka.admin import KafkaAdminClient
from kafka.errors import UnknownTopicOrPartitionError, TopicAlreadyExistsError
def delete_kafka_topic(admin_client, topic_name):
"""
Deletes a specific Kafka topic.
Args:
admin_client (KafkaAdminClient): The admin client connected to Kafka.
topic_name (str): The name of the topic to delete.
"""
print(f"Attempting to delete topic: '{topic_name}'...")
try:
# The delete_topics method expects a list of topic names
admin_client.delete_topics(topics=[topic_name])
print(f"Successfully initiated deletion for topic: '{topic_name}'.")
print("Note: Deletion in Kafka is asynchronous and may take a moment to complete on the broker.")
except UnknownTopicOrPartitionError:
print(f"Error: Topic '{topic_name}' does not exist. Nothing to delete.")
except Exception as e:
print(f"An unexpected error occurred: {e}")
if __name__ == "__main__":
admin = None # Initialize admin to None
try:
# Create a KafkaAdminClient instance
admin = KafkaAdminClient(
bootstrap_servers=broker_servers,
client_id='my_consumer_group'
)
# Call the function to delete the topic
delete_kafka_topic(admin, topic_to_create)
except Exception as e:
print(f"Failed to connect to Kafka or create admin client: {e}")
finally:
# Ensure the admin client connection is closed
if admin:
print("Closing admin client.")
admin.close()
Attempting to delete topic: 'cctv'...
Successfully initiated deletion for topic: 'cctv'.
Note: Deletion in Kafka is asynchronous and may take a moment to complete on the broker.
Closing admin client.
List Topics#
from kafka.admin import KafkaAdminClient
# Define the Kafka broker (adjust the host/port as needed)
# Create an admin client
admin_client = KafkaAdminClient(bootstrap_servers=broker_servers)
# Fetch the list of topics
topics = admin_client.list_topics()
# Print the list of topics
print("Kafka Topics:", topics)
# Close the admin client
admin_client.close()
Kafka Topics: []
Delete All Topics and All Consumer Groups in a Kafka Cluster#
“⚠️ This is a destructive operation and cannot be undone.”
%pip install --quiet -U confluent-kafka
Note: you may need to restart the kernel to use updated packages.
# --- 1. Import necessary libraries ---
from confluent_kafka.admin import AdminClient
from confluent_kafka import KafkaException
# --- 2. Define the functions ---
def delete_topics(admin_client, topic_names):
"""Deletes a list of topics."""
if not topic_names:
print("🔵 No topics found to delete.")
return
print(f"\nProceeding to delete {len(topic_names)} topic(s)...")
# Delete topics; this returns a dictionary of futures
fs = admin_client.delete_topics(topic_names)
# Wait for each operation to complete
for topic, f in fs.items():
try:
f.result() # The result() will raise an exception if the deletion failed
print(f"✅ Topic '{topic}' deleted successfully.")
except KafkaException as e:
print(f"❌ Failed to delete topic '{topic}': {e}")
except Exception as e:
print(f"❌ An unexpected error occurred while deleting topic '{topic}': {e}")
def delete_consumer_groups(admin_client, group_ids):
"""Deletes a list of consumer groups."""
if not group_ids:
print("🔵 No consumer groups found to delete.")
return
print(f"\nProceeding to delete {len(group_ids)} consumer group(s)...")
# Delete consumer groups; this returns a dictionary of futures
fs = admin_client.delete_consumer_groups(group_ids)
# Wait for each operation to complete
for group, f in fs.items():
try:
f.result() # The result() will raise an exception if the deletion failed
print(f"✅ Consumer group '{group}' deleted successfully.")
except KafkaException as e:
print(f"❌ Failed to delete consumer group '{group}': {e}")
except Exception as e:
print(f"❌ An unexpected error occurred while deleting group '{group}': {e}")
# --- 3. Set your server and run the script ---
if __name__ == '__main__':
# ⚠️ IMPORTANT: This is set to the address you provided.
BOOTSTRAP_SERVER = '172.200.204.244:9092'
# The exact phrase you must type to confirm the action.
confirmation_phrase = "delete_all"
# Create a single AdminClient instance
admin_config = {'bootstrap.servers': BOOTSTRAP_SERVER}
admin_client = AdminClient(admin_config)
print(f"🔎 Connecting to {BOOTSTRAP_SERVER} to list items...")
topic_names_to_delete = []
group_ids_to_delete = []
try:
# List all topics
topics_metadata = admin_client.list_topics(timeout=10).topics
topic_names_to_delete = list(topics_metadata.keys())
# List all consumer groups
list_groups_future = admin_client.list_consumer_groups()
groups_result = list_groups_future.result()
group_ids_to_delete = [g.group_id for g in groups_result.valid]
print("\n--- Items Scheduled for Deletion ---")
if topic_names_to_delete:
print(f"Topics: {topic_names_to_delete}")
else:
print("Topics: None found.")
if group_ids_to_delete:
print(f"Consumer Groups: {group_ids_to_delete}")
else:
print("Consumer Groups: None found.")
print("------------------------------------\n")
# If there's nothing to delete, exit gracefully.
if not topic_names_to_delete and not group_ids_to_delete:
print("🎉 Nothing to delete. Exiting.")
exit()
except KafkaException as e:
print(f"❌ Error connecting to Kafka or listing items: {e}")
exit()
except Exception as e:
print(f"❌ An unexpected error occurred: {e}")
exit()
# Prompt the user for confirmation.
print("⚠️ This is a destructive operation and cannot be undone.")
user_input = input(f"To proceed, please type '{confirmation_phrase}' and press Enter: ")
# Check if the user's input matches.
if user_input == confirmation_phrase:
print("\n✅ Confirmation received. Proceeding with deletion...")
# Execute the functions with the pre-fetched lists
delete_topics(admin_client, topic_names_to_delete)
print("-" * 20)
delete_consumer_groups(admin_client, group_ids_to_delete)
print("\n🎉 Operation complete.")
else:
print("\n❌ Operation cancelled. The input did not match.")
🔎 Connecting to 172.200.204.244:9092 to list items...
--- Items Scheduled for Deletion ---
Topics: None found.
Consumer Groups: ['cctv_reprocessing', 'cctv_consumer']
------------------------------------
⚠️ This is a destructive operation and cannot be undone.
To proceed, please type 'delete_all' and press Enter: delete_all
✅ Confirmation received. Proceeding with deletion...
🔵 No topics found to delete.
--------------------
Proceeding to delete 2 consumer group(s)...
✅ Consumer group 'cctv_reprocessing' deleted successfully.
✅ Consumer group 'cctv_consumer' deleted successfully.
🎉 Operation complete.