Bulk Import from S3#
This pipeline leverages Apache NiFi 2.x to extract objects from the VAST Datastore that contain Parquet files. The data is then imported into the VAST Database using the bulk import functionality.
The ingestion process occurs directly on the VAST CNODES, enabling data to flow seamlessly from the Datastore to the Database without passing through the NiFi servers. This direct transfer significantly optimizes the data pipeline by minimizing latency and resource consumption on the NiFi infrastructure.
Configure ListS3 Processor
Configure VastDB Processor
Note: This functionality is currently limited to Parquet files.
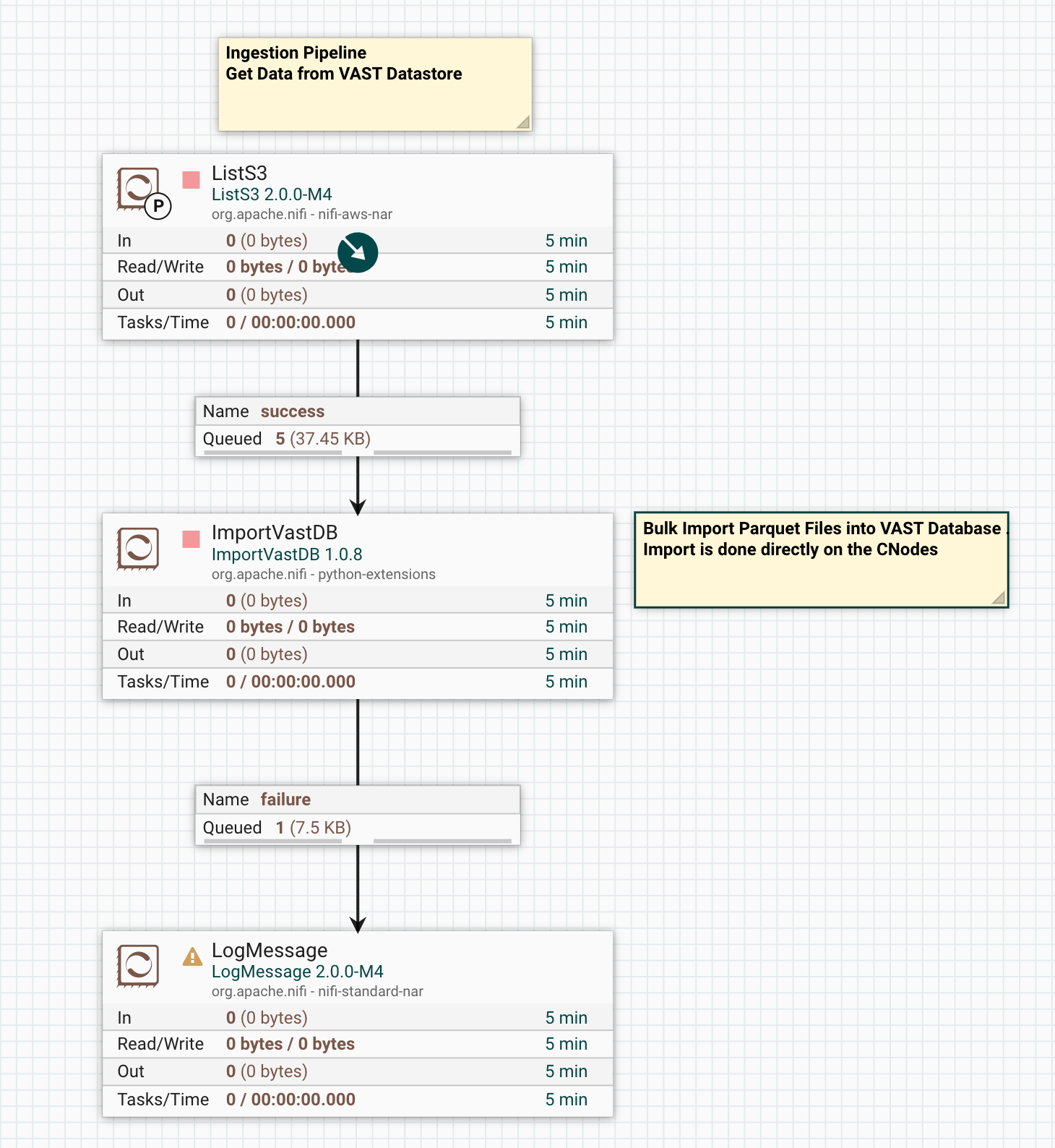
ListS3 Processor#
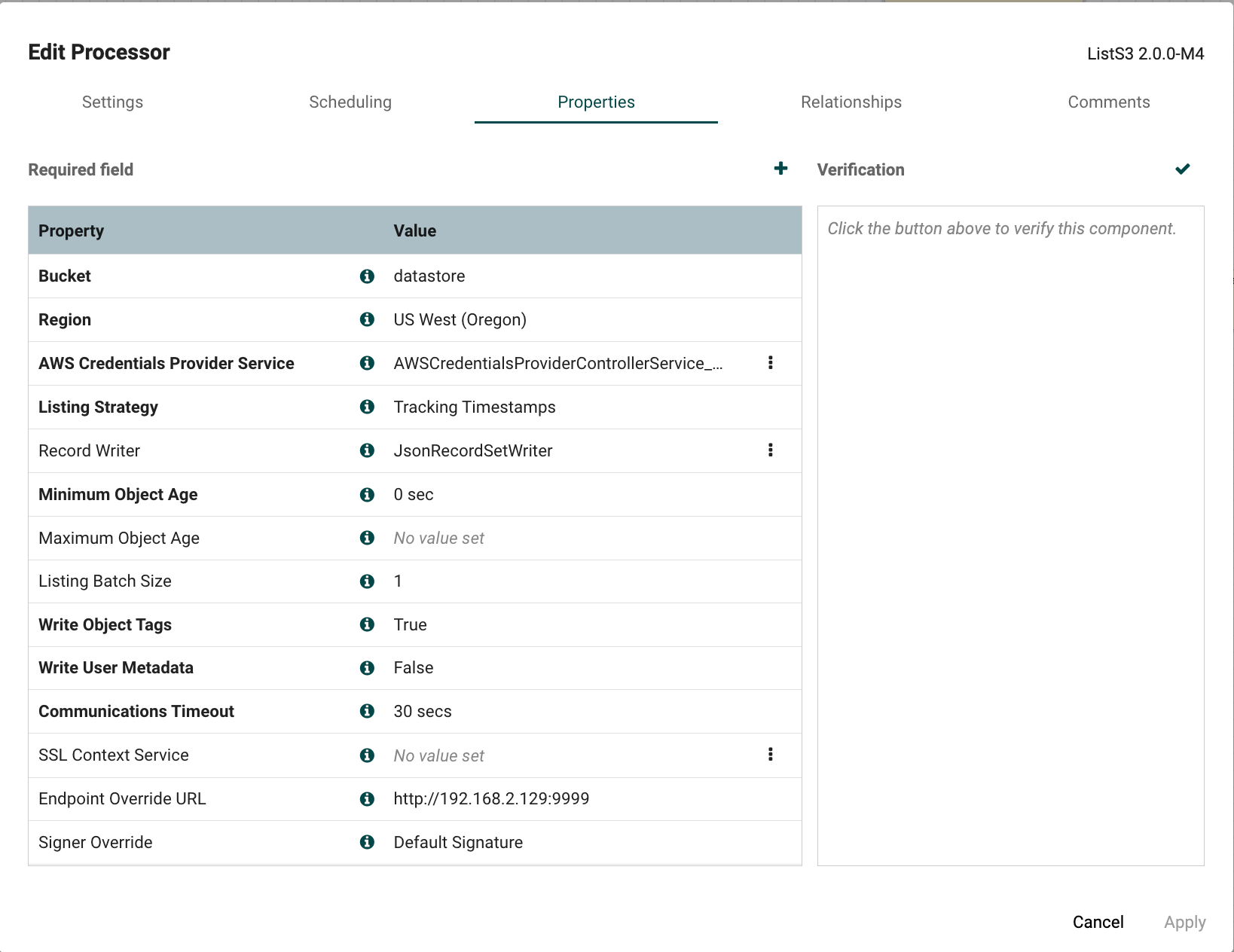
Configure the ListS3 Processor#
Bucket: Specify the name of the S3 bucket you want to monitor for objects.
Prefix: Set the path to your objects within the bucket (e.g., data/parquet/), allowing the processor to list only the files within this directory.
Record Writer: Configure the appropriate Record Writer to format the listed S3 data as needed.
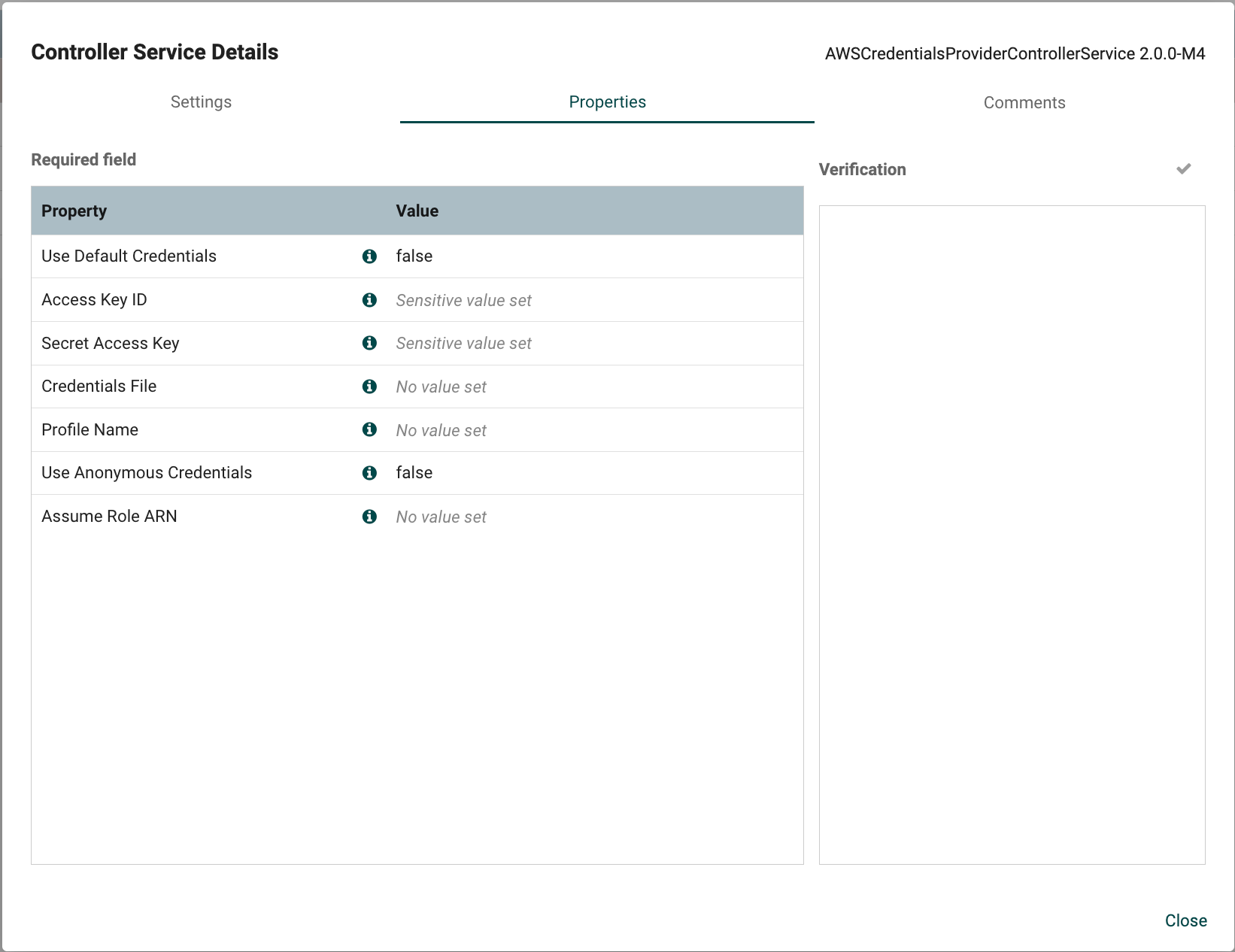
AWS Credential Providers:
Access Key: Enter your AWS Access Key.
Secret Key: Enter your AWS Secret Key.
Endpoint Override URL: Set the VAST Datastore S3 endpoint (VIP) and port to connect to the VAST S3-compatible service.
ImportVASTDB Processor#
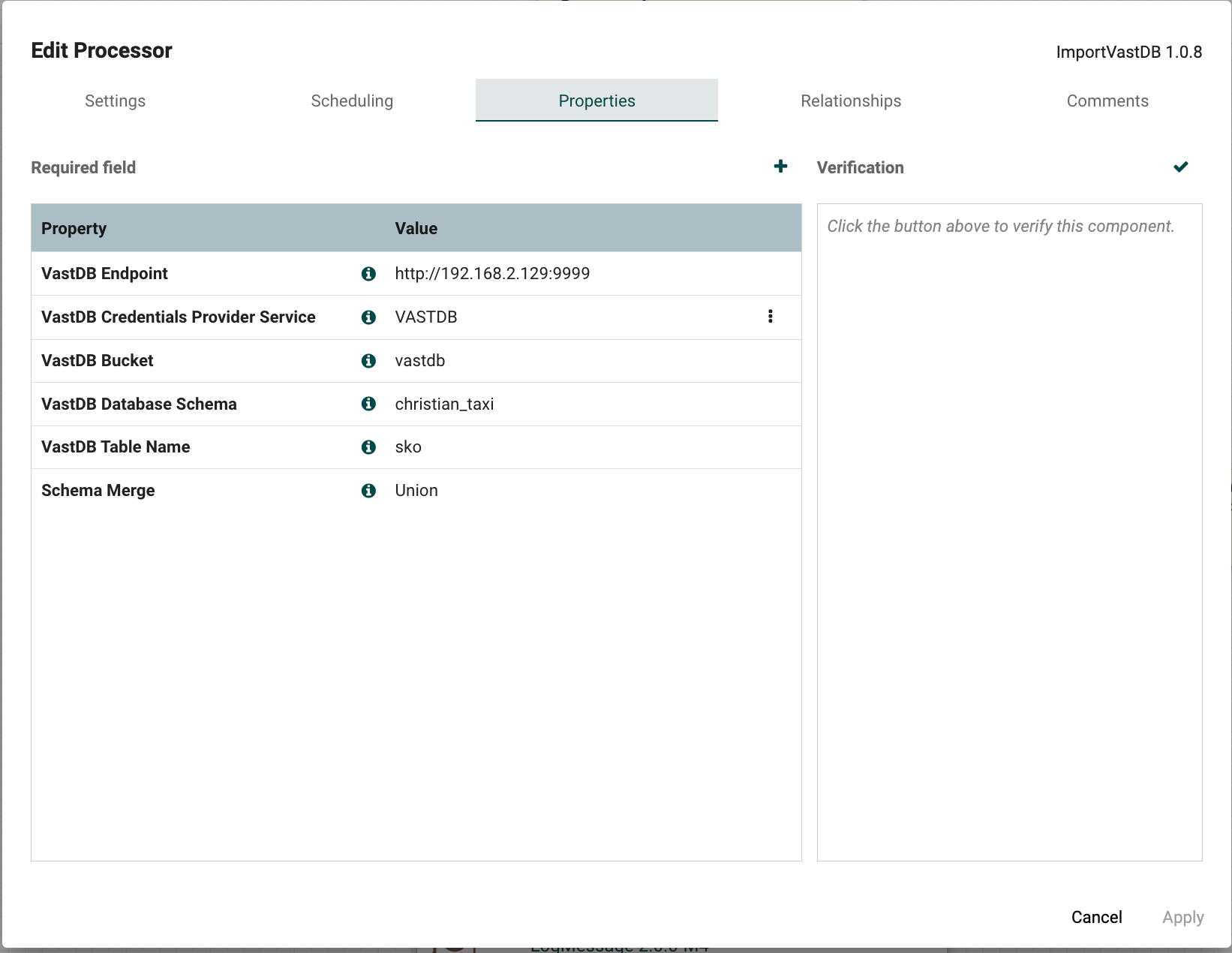
Configuring the ImportVASTDB Processor#
VAST DB Endpoint: Specify the endpoint URL for your VAST Database, which will be used to establish the connection.
Credential Provider: Provide the credentials for accessing the VAST Database. Ensure that you have an IAM policy with write permissions defined for these credentials.
Database Schema: Enter the name of the database schema where the data will be imported.
Table Name: Specify the target table name in the VAST Database where the imported data will be stored.