Table Management#
Important
This notebook is in the process of being migrated to Vast Data Platform Field Docs. It will probably not run yet.
See also
The Vast DB SDK API Documentation is available here.
The creation of any high-level entity (database, table, column) is a metadata operation. There is no pre-allocation of space for data. Top level objects in the element store are updated and any new data associated with them is ready to be linked when written.Creation The creation of any high-level entity (database, table, column) is a metadata operation. There is no pre-allocation of space for data. Top level objects in the element store are updated and any new data associated with them is ready to be linked when written.
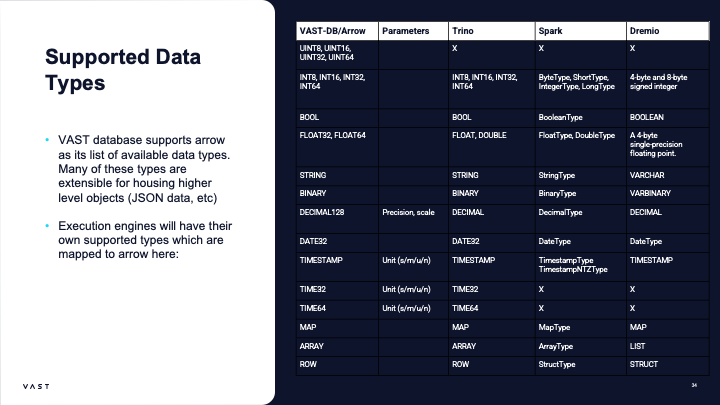
VAST DB provides support for the following data types:
Install sdk and connect to Vast DB#
Install vastdb library.
!pip install --quiet vastdb
# Change these variables to reflect your environment, E.g.
#
# ENDPOINT = 'http://your_vast_endpoint:12345'
# DATABASE_NAME = 'your_db'
# ACCESS_KEY = 'your_access_key'
# SECRET_KEY = 'your_secret_key'
# DATABASE_SCHEMA = 'your_database_schema'
#
# This will be created:
# TABLE_NAME='python_sdk_demo'
Connect to Vast DB
import vastdb
session = vastdb.connect(
endpoint=ENDPOINT,
access=ACCESS_KEY,
secret=SECRET_KEY)
Table Management API#
create_table#
Usage: Create a new table in a specified schema.
Parameters:
table_name(str): Name of the table to create.columns(pyarrow.Schema): Arrow Schema object (pyarrow.Schema documentation)fail_if_missing(bool, opt, default=True) If True, fail with an exception if the schema doesn’t exist, else return Noneuse_external_row_ids_allocation=False(bool, opt, default=False) TBC
import pyarrow as pa
from vastdb.errors import TableExists
# Table schemas (don't confuse with database schema) are created using
# PyArrow (pa)
ARROW_SCHEMA = pa.schema([('column1', pa.int32()), ('column2', pa.string())])
with session.transaction() as tx:
bucket = tx.bucket(DATABASE_NAME)
# first retrieve the schema
try:
schema = bucket.schema(name=DATABASE_SCHEMA, fail_if_missing=False)
print(schema)
except Exception as e:
print("Schema doesn't exist:", e)
if schema:
try:
table = schema.create_table(table_name=TABLE_NAME, columns=ARROW_SCHEMA)
print(f"Table created: {table.name}")
except TableExists as e:
print("Couldn't create table because it already exists:", e)
except Exception as e:
print("Couldn't create table:", e)
The cell below is a boilerplate code - it is hidden by default.
Show code cell content
def print_tables(database_name=DATABASE_NAME, schema_name=DATABASE_SCHEMA):
print(f"Listing tables in: database='{database_name}' schema='{schema_name}'")
with session.transaction() as tx:
schema = tx.bucket(database_name).schema(name=schema_name, fail_if_missing=False)
if not schema:
print(f">>> Schema {schema_name} not found.")
return
if not schema.tables():
print(">>> No tables found.")
for table in schema.tables():
print(f">>> Table: '{table.name}'")
print_tables(database_name=DATABASE_NAME, schema_name=DATABASE_SCHEMA)
tables#
Usage: List all tables in a schema.
Parameters:
table_name(str, optional, default=None): Only return tables matching the exact table_name.
with session.transaction() as tx:
schema = tx.bucket(DATABASE_NAME).schema(DATABASE_SCHEMA)
table = schema.tables(table_name=TABLE_NAME)
print(table)
# what happens if the table doesn't exist?
with session.transaction() as tx:
schema = tx.bucket(DATABASE_NAME).schema(DATABASE_SCHEMA)
table = schema.tables(table_name='non-existing-table')
print(table)
# For comparison let's list all the tables using our utility function
# created earlier in this notebook.
print_tables(database_name=DATABASE_NAME, schema_name=DATABASE_SCHEMA)
get_stats#
Usage: Obtain statistics about a specific table.
Parameters:
No parameters
TABLE_NAME='pythonsdk'
with session.transaction() as tx:
schema = tx.bucket(DATABASE_NAME).schema(DATABASE_SCHEMA)
table = schema.table(name=TABLE_NAME, fail_if_missing=False)
if table:
print(f"Getting table stats {table.name}")
print(table.get_stats())
drop#
Usage: Delete a table.
Parameters:
No parameters
# Create a table and then drop it.
with session.transaction() as tx:
bucket = tx.bucket(DATABASE_NAME)
# first retrieve the schema
try:
schema = bucket.schema(name=DATABASE_SCHEMA, fail_if_missing=False)
print(schema)
except Exception as e:
print("Schema doesn't exist:", e)
if schema:
try:
arrow_schema = pa.schema([('column1', pa.int32()), ('column2', pa.string())])
table = schema.create_table(table_name='TEMPORARY_TABLE', columns=arrow_schema)
print(f"Table created: {table.name}")
except TableExists as e:
print("Couldn't create table because it already exists:", e)
except Exception as e:
print("Couldn't create table:", e)
# first let's list the tables
print_tables(database_name=DATABASE_NAME, schema_name=DATABASE_SCHEMA)
Now drop the table.
with session.transaction() as tx:
schema = tx.bucket(DATABASE_NAME).schema(DATABASE_SCHEMA)
table = schema.table(name='TEMPORARY_TABLE', fail_if_missing=False)
if table:
print(f"Dropping table {table.name}")
table.drop()
Verify the table no longer exists.
print_tables(database_name=DATABASE_NAME, schema_name=DATABASE_SCHEMA)